Supernan1994's Personal Blog
一个专业词汇聚类实践
在搭建对话机器人(QA)过程中,我们通常需要对客户的语料做一些专业词汇的挖掘。不同领域的客户挖掘出来的专业词汇差异性很大:
- 酒类行业:产品名;口感;颜色;送礼场景(如结婚、家庭聚会等)
- 母婴行业:宝宝、妈妈的各种说法;新生儿会得的各种疾病;不舒服时表现的各种症状
我在网上找了疫情相关的问答对语料,语料是短文本问答对,挖掘的时候用了标准问题和相似问题两列。我们来看下挖掘的效果:
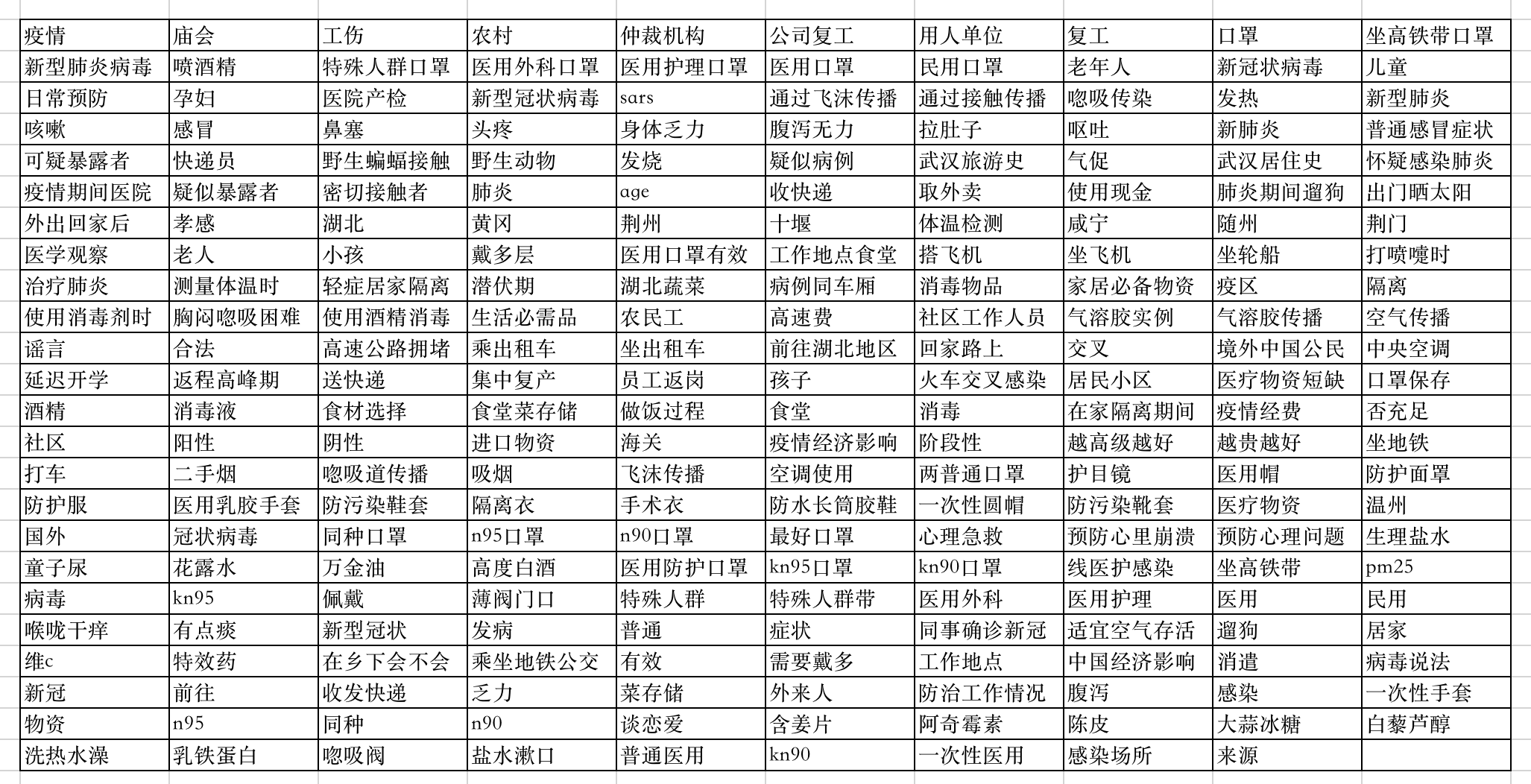
专业词汇挖掘有很多种方法,比如无监督的TFIDF、左右熵、互信息;半监督的模板+bootstrap+清洗筛选;有监督的神经网络+CRF等。上面看到的效果是在一个空知识库里导入语料挖掘的结果,是参考KDD ‘19腾讯发表的concepT思路开发的;当词库里有已经标注好的专业词汇时也会走CRF模型。关于挖掘在这里就不细说了。
挖掘出来的专业词汇主要用途有:
- 作为专业词汇影响分词
- 作为多轮对话的词槽
- 作为句式触发器的词槽
后两种用法都要求对专业词汇聚类,3举个例子:
身体乏力是新型肺炎的症状吗?
感觉自己乏力怎么办?
腹泻无力是新型冠状肺炎的症状吗?
腹痛腹泻怎么办?
呕吐是新肺炎的症状吗?
如果知道乏力,腹泻,呕吐都是新冠症状,新型肺炎,新型冠状肺炎,新肺炎说的都是一回事儿,那就可以帮助机器把这些query作为一类的知识点聚类,保存为句式,提高知识库的泛化能力和可维护性:
{@症状}是{@新冠}的症状吗?
感觉自己{@症状}怎么办?
{@症状}怎么办?
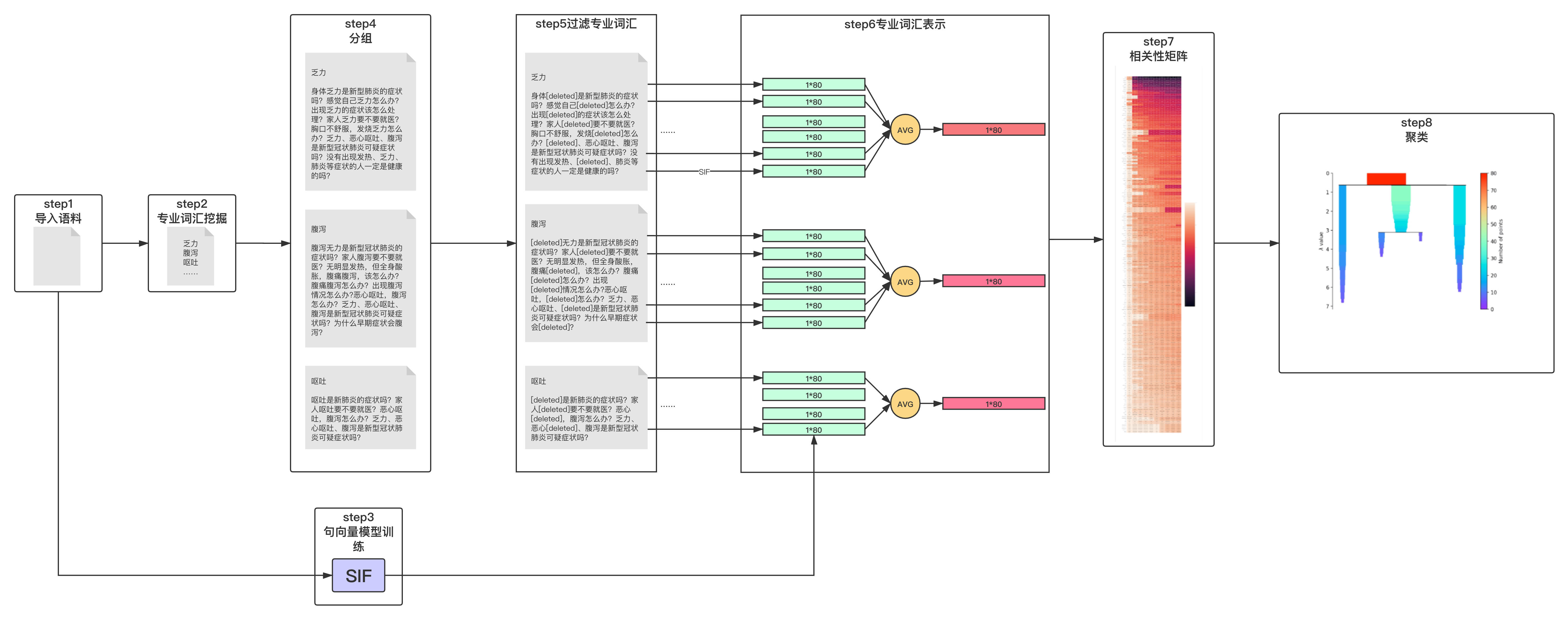
1. 方法
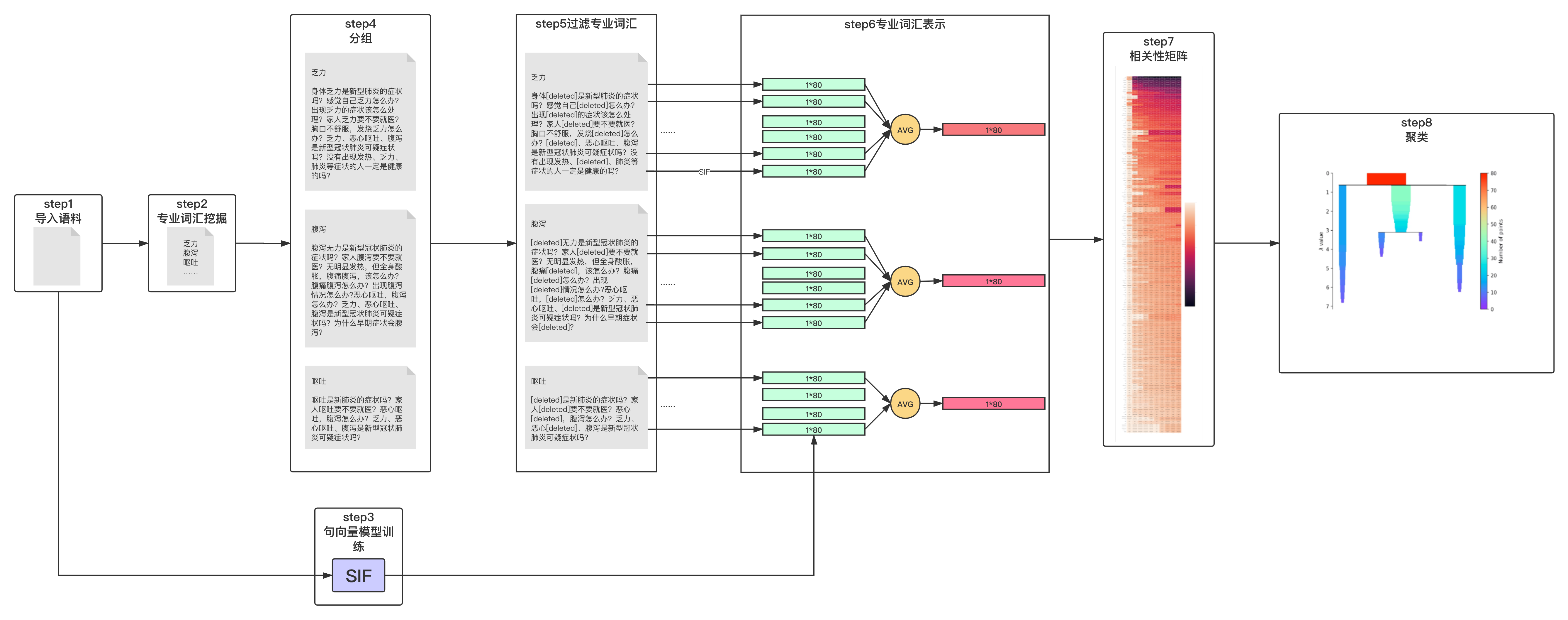
思路:从query里去掉专业词汇,用query的其他词编码的句向量表示专业词汇的词向量,通过余弦距离进行层次聚类。
STEP 1: 导入相似问语料(短query)。
STEP 2: 挖掘专业词汇。
STEP 3: 训练SIF句向量模型。
SIF是ICLR ‘17的论文,提出了一种非常简单的句向量表示算法,可以说是除了词向量相加取平均之外最简单的算法,但在文本相似度的任务里能够击败RNN和LSTM。对比词向量相加取平均主要有两点改进:
1)用逆词频对词向量做了调权,相加作为句向量。
2)用PCA对句向量做降维,让句向量更多的保留该句特征,减少全局特征。
STEP 4: 根据专业词汇对query分组,包含该专业词汇的分到该组,如果有多个专业词汇,在多个组里出现。
STEP 5: 对于匹配到专业词汇的每个query,删除专业词汇,得到剩余的文本。
STEP 6: 用SIF模型对去掉专业词汇的query做编码,把一个专业词汇对应的分组里所有句向量相加取平均,得到专业词汇的向量表示。
STEP 7: 用余弦相似度计算相关性矩阵。
STEP 8: 用HDBSCAN进行层次聚类。
HDBSCAN的优点在于超参数较少,不需要设置分类的个数,可以发现异常点不对异常点聚类。
HDBSCAN超参数设置的思路是:
1)保证对当前挖掘出来的专业词汇,保证召回率为40%时,将参数设计的尽可能保守,提高准确率。召回率40%在当前的场景问题不大,因为当AI训练师对已聚类的专业词汇审核后,再发起一次专业词汇挖掘,挖掘出的词汇会通过CRF匹配到已标注的专业词汇类别上,匹配不到的会重走聚类流程。
2)由于通常数据集较小,所以每个簇最少的专业词汇设置为2。
2. 效果
2.1 相关性矩阵
下图颜色越浅代表越相似,越深代表越不相似。可以看到专业词汇表示的效果相当不错,能够学到相关性,而且相关性有一定区分度。

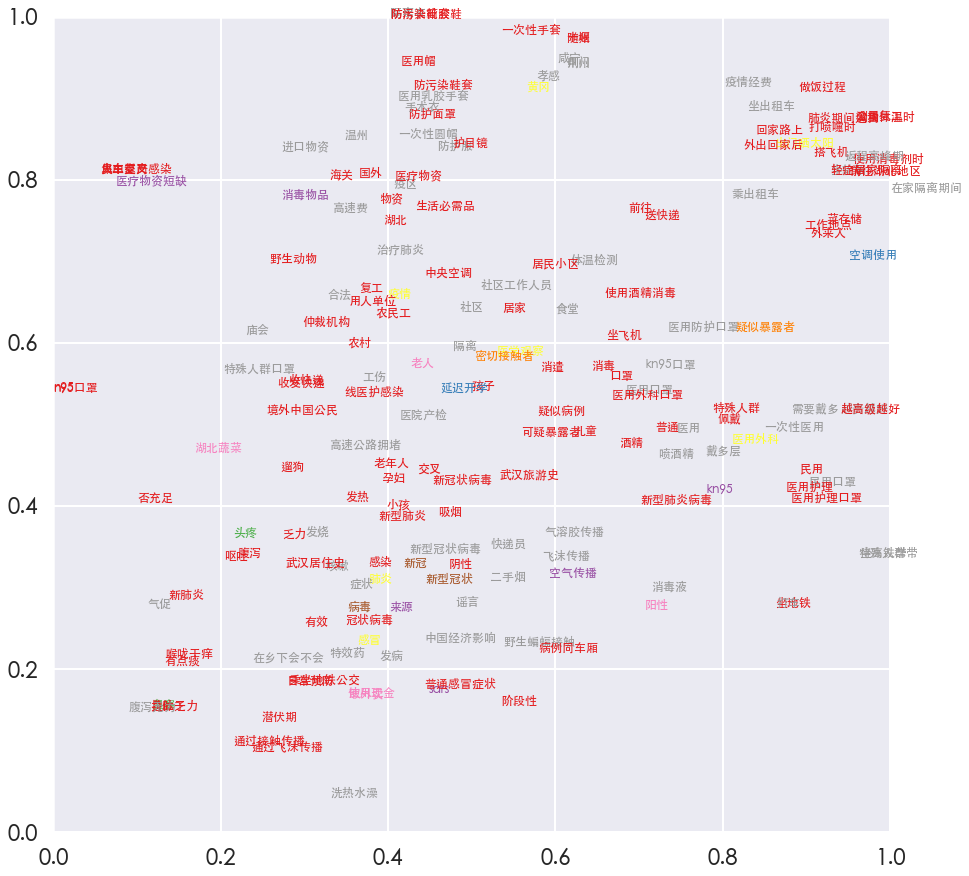
2.2 降维分布

2.3 聚类结果
-1代表没有召回的专业词汇。

聚类可视化:
撒花🌸~
Written on September 6th, 2020 by supernan1994