Supernan1994's Personal Blog
工程团队需要注意的20个工作模式

- 0. 背景
- 1. 个人层面的工作模式
- 2. 团队层面的工作模式
- 模式11:需求变更 (Scope Creep)
- 模式12:产品把控能力不足 (Flaky Product Ownership)
- 模式13:不在规划中的大规模重构 (Expanding Refactor)
- 模式14:临上线前提交PR (Just One More Thing)
- 模式15:不经思考的merge PR (Rubber Stamping)
- 模式16:知识谷仓 (Knowledge Silos)
- 模式17:合并自己的PR (Self Merging PRs)
- 模式18:长时间无法merge的PR (Long Running PRs)
- 模式19:高巴士因子 (High Bus Factor)
- 模式20:迭代复盘 (Sprint Retrospectives)
0. 背景
GitPrime是一家做企业服务的公司。基于对工程团队代码仓库的pull request和code review的数据统计,GitPrime可以产出直观的图表,帮助管理者更高效的发现团队内部存在的问题。
GitPrime认为高效的管理者会把团队看做有多个模块相互依赖的系统,每个模块都有自己的输入和输出。当输入和输出不符合预期时,『数据』可以在探索问题的根本原因的过程中产生重要价值。20 Patterns to Watch for in Your
Engineering Team这本书是GitPrime与上百家公司的合作时,总结出来的20个常见的工作模式。他们希望这本书可以帮助团队更好的认识成就、发现瓶颈,用数据驱动的方式debug研发流程。
这篇文章主要是基于我的理解对这本书进行的翻译和提炼。
1. 个人层面的工作模式
模式1:领域冠军 (Domain Champion)

领域冠军是某个服务的专家,他们清楚这个服务所有代码的细节,可能这些代码基本都是他写的。在对深度要求比较高的场景下,企业是需要有这种员工的。管理者需要保证这个领域的知识不能成为单点,并且鼓励领域冠军拓展知识广度。
1)如何发现他们?
- 总是修改某一个服务的代码,也会经常删减和重构
- 频繁的提交大小适中的commit,能够较好的控制开发节奏
- 由于没有人比他更了解这段代码,review时很少有人可以提出有效反馈。他也很少接受他人意见。
2)如何处理这种情况?
- 认可他在专业上的成就,鼓励在团队中分享经验
- 给他分配一些其他感兴趣的任务,在新的任务中应用并分享过去积累的最佳实践
很多人都喜欢呆在自己的舒适区,好的管理者需要推动他们走出来,提升团队同学的知识广度,减少系统的单点风险。
模式2:囤积代码 (Hoarding the Code)

囤积代码指总是自己写代码,到迭代结束的时候才提交一个超大的PR的工作习惯。这种做法会导致代码提交上来之后,因为时间原因,reviewer不能充分review所有代码,增加产生问题的概率;即使发现了问题,也不一定有时间改正,如果是设计上有问题,可能需要推翻重做。
1)如何发现他们?
- 低频率提交超大的commit
- 快上线时提交PR
- review时间较长,review覆盖率较低,review意见采纳率较低
2)如何处理这种情况?
- 有同理心,确定工程师有足够的时间完成这个任务
- 找一个非正式的场合,聊聊最近的工作状态,认可他们的成就。在此过程中提出团队合作的价值:可以相互学习、从不同角度看问题、减少不确定性、发现更好的解决方案。在实践中,不需要等到全部ready再提PR。
模式3:大量废代码 (Unusually High Churn)

废代码是在写完之后很快就做了重写的代码。从统计数据上看,提交的代码一般有13-30%会作废,这里面包括一些测试、POC和必要的重构。超过这个范围说明团队或个人可能在非常痛苦的完成任务。这个问题可能由3种原因造成:
- 完美主义
- 纠结,不知道该如何实现
- 外部原因:需求产生的晚/不明确/发生变更
1)如何发现他们?
- 迭代后期产生的废代码显著提高,超过正常比例
2)如何处理这种情况?
- 如果是外部原因,如需求变更导致的问题:
- 用数据说话,告诉产品经理由于需求变更产生的额外工作量和负面影响
- 把需求放到下一个迭代或者拆分为多个迭代完成
- 如果是内部原因:
- 写代码前提前拆分工作,先想清楚怎么做再开始写
- 提前做(可以在设计阶段就做) review
- 让资深工程师说明什么是目前阶段足够好的实现,避免过度设计
- 如果问题对当前工程师来说比较困难,找另外一个工程师一起完成
模式4:百发百中 (Bullseye Commits)

这种情况指:工程师能够很好的理解需求,并将需求拆分为小的任务,提交的代码基本不需要修改。
1)如何发现他们?
- 提前完成,而不是到截止日期才提交
- 大小合适
- 被充分review
- 第一次review就通过
2)如何处理这种情况?
- 面对面或在code review中留言肯定
- 跟总是可以做到的人学习经验,或者让他在review别人代码的时候提供反馈
模式5:个人英雄主义 (Heroing)

“英雄”总是能在最后一秒钟修复别人的问题。但这个做法会导致几个问题:
- 破坏了review的正反馈的循环
- 可能会造成团队同学的自我怀疑
- 可能会导致团队内部滋生一种懒惰的氛围:习惯性觉得有人会替自己解决问题
- 上线前的紧急修复会导致技术债的诞生
1)如何发现他们?
- 代码提交的比较晚
- 自己合并PR
- 很少接受别人的review建议(也有可能是其他人很少能提出有效建议)
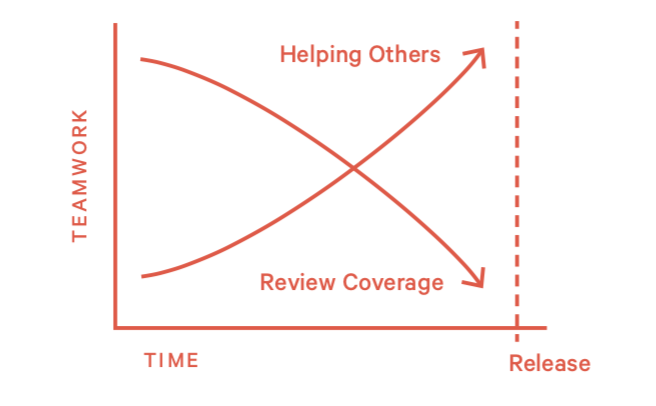
2)如何处理这种情况?
- 团队成员提交更频繁、更小的commit。大型项目提交中期PR。更早的发现问题。
- 推动形成更健康的合作模式。将直接修改代码的行为转变为code review。
模式6:过度帮助 (Over Helping)

过度帮助指一个工程师花费过多时间帮助其他工程师完成工作(一个人是另一个的mentor的情况除外)。这个问题会带来几个后果:
- 过多的帮助其他同学打扫战场会导致个人工作完成度不高
- 减少其他同学独立思考的机会
- 产生资源浪费
1)如何发现他们?
- 两个人总是互相review。从统计数据上看,其中一个经常给别人review代码、review意见经常被采纳。另一个人相反
- 代码总是在上线前一秒钟被修正
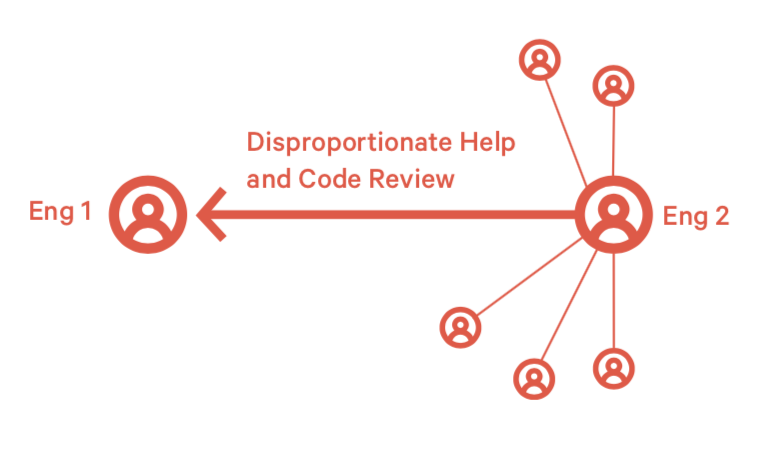
2)如何处理这种情况?
- 让其他工程师介入review流程
- 让两个人负责不同的模块
- 给高级工程师一个有挑战的工作
- 更强的那一方展示出自然的领导力和教练倾向,找机会让他在团队中施展这个才华
分开两个人并不是破坏友谊,而是让知识在团队中更均匀的分布,同时磨练团队里同学的能力,让他们的职业生涯得到成长。
模式7:随手收拾 (Clean As You Go)

习惯于随手收拾代码工程师会注意到已有代码的缺陷并改进它,即使跟当前正在做的任务没什么关系。这是一件非常值得鼓励的工作习惯。
比起实现业务功能,改进的工作往往不会得到很多关注,但对于团队来说时无价的。管理者应该鼓励这种行为。
1)如何发现他们?
- 加了一些新代码,对周围的旧代码做了较多修改
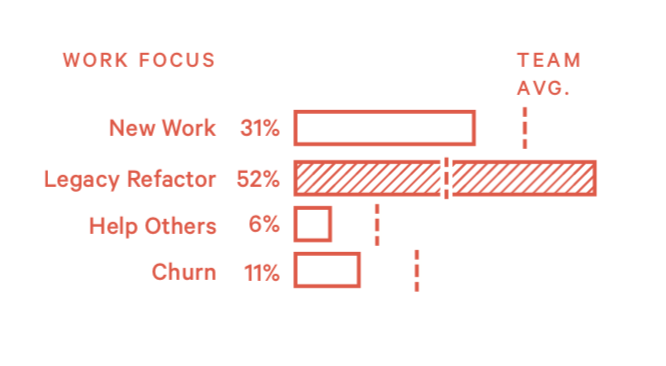
2)如何处理这种情况?
- 在公开场合认可这个工程师的工作,并鼓励大家学习。可以经常在迭代复盘会和站会上提到这类贡献,这样每个人都会知道你重视这件事情
- 在团队中推广开发规范
模式8:得心应手 (In the Zone)

这类工程师能够持续稳定的输出高质量的代码。软件开发是一场持久战,如果想获得可持续的商业价值,必须要保证每天都有产出,真正有价值的创意可能需要花几年来实现。
1)如何发现他们?
- 活跃天数高于平均值
- PRs准时、大小合适
- 持续参与review
- 废代码比例较低
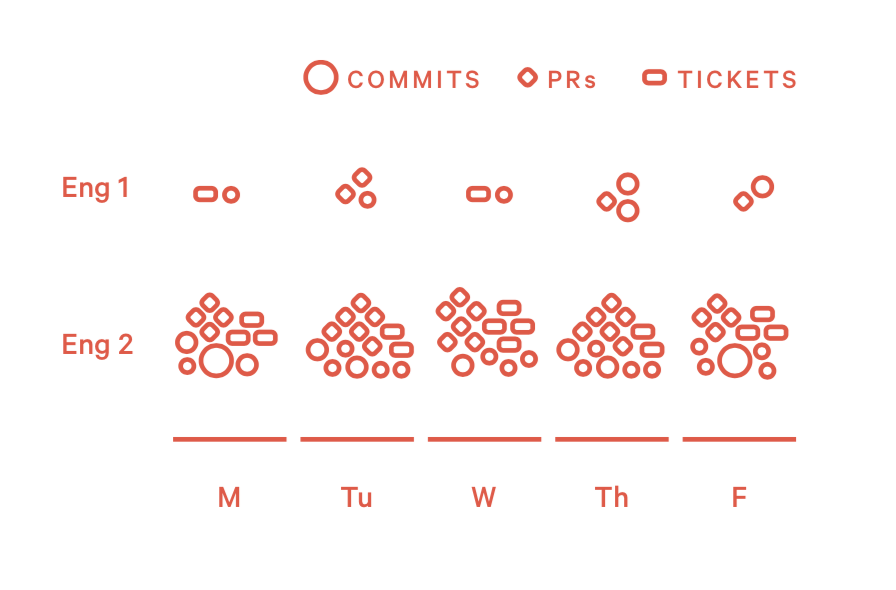
2)如何处理这种情况?
- 公开、私下鼓励,赞美始终如一的坚持
- 为每个团队成员找到让他们得心应手的工作
- 减少工程师被打扰的时间
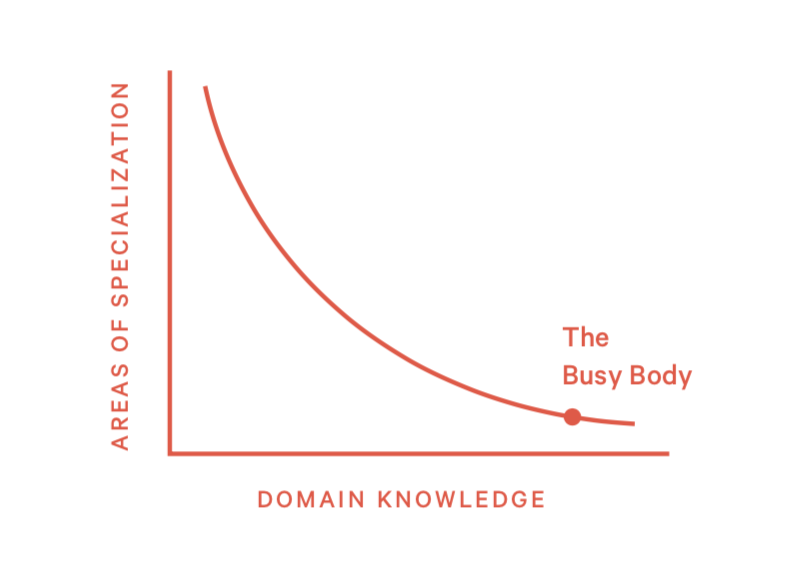
模式9:乱试一通 (Bit Twiddling)

这种模式是形容像拼拼图一样工作,乱试一通,期望最后得到正确的结果。这通常是因为工程师没有充分理解问题,或者不知道这次改动的背景。
这种情况下,工程师可能会失去工作动力,而且很容易给线上引入bug。
1)如何发现他们?
- 较高的废代码率
- 反复修改不重要的代码(如标准库),reviewer也并不关心这个改动
2)如何处理这种情况?
- 找一个新的项目
- 找一个更小的需求
创造性工作者会在解决新的、有挑战的问题中得到成长。新的经历会使他们有新的收获,这个是大多数工程师都喜欢做的事情。
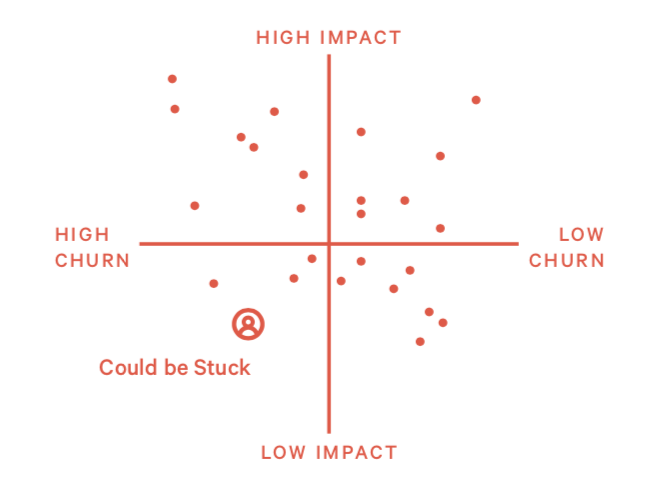
模式10:打杂 (The Busy Body)

打杂的工程师是指在多个代码仓库中缝缝补补:一会儿解决前端问题,一会儿做个重构,一会儿去搞数据库的人。解决的问题通常来说比较轻量。
如果是短期表现没什么问题。但长时间如此会造成工程师没有太多主人翁意识,因为没有一个项目是他从头到尾做完的。这也会导致人员流失。
1)如何发现他们?
- 在很多仓库里提交小的PR
- 因为改动是别人的代码,code review中会有比较多的讨论
- 更多时间在增加新功能。而在修复bug、优化代码方面投入较少
2)如何处理这种情况?
- 给他一个需要从0到1搭建的系统化模块,要求不仅仅是做完,也要在这个领域积累足够的技术深度
- 持续迭代。继续给一些修复bug,单元测试,文档撰写的任务
- 请他分享过程中的经验教训和最佳实践
以上过程的关键是培养工程师的主人翁意识。
2. 团队层面的工作模式
模式11:需求变更 (Scope Creep)

这种情况是指,已经开始开发的情况下产生需求变更。即使设计最好的系统也会有需求变更的情况出现。管理者需要尽可能避免这种事情的发生。
1)如何发现这个问题?
- 临上线前提交大量代码,而且没有经过code review
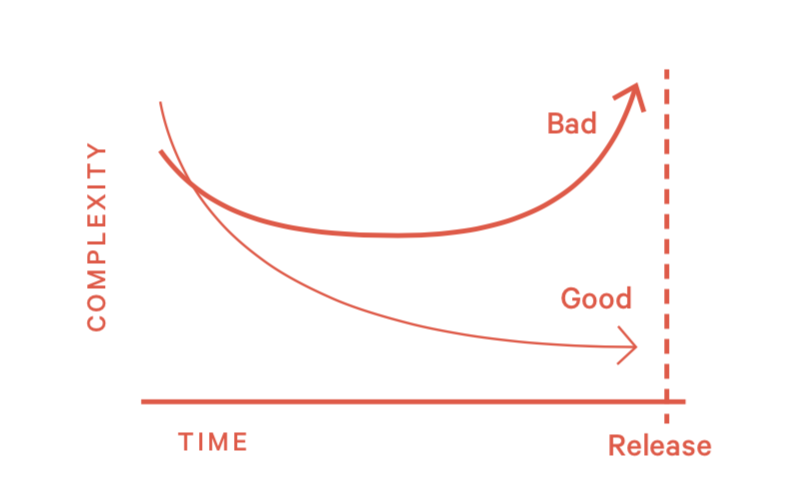
2)如何处理这种情况?
- 需求变更是因为产品设计时考虑的不全面,不应该工程师承担这个后果
- 让产品经理意识到考虑不周带来额外工作量
模式12:产品把控能力不足 (Flaky Product Ownership)

把控能力不足的产品经理通常有两种表现:
- 需求不完善,需要工程师细化
- 开始开发后变更需求导致延期
1)如何发现这个问题?
- 在某个产品经理身上总是出现这个问题
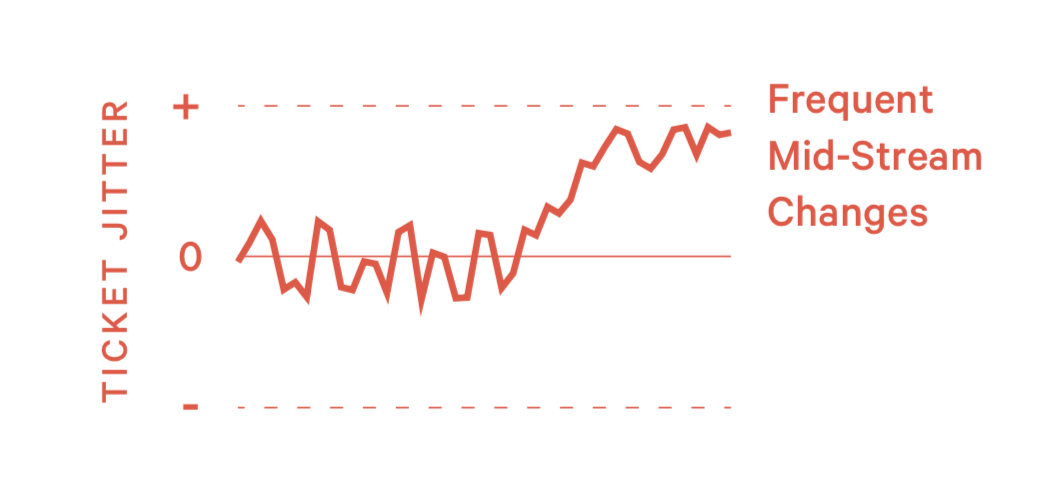
2)如何处理这种情况?
- 可能是因为这个产品经理,工作太多,没有足够的精力。跟产品负责人沟通,可以一起帮他解决这个问题。
模式13:不在规划中的大规模重构 (Expanding Refactor)

这种情况是指,本来想做一个小的优化最后变成了大范围重构。
1)如何发现这个问题?
- 大规模重构,并且对未来的规划没有收益
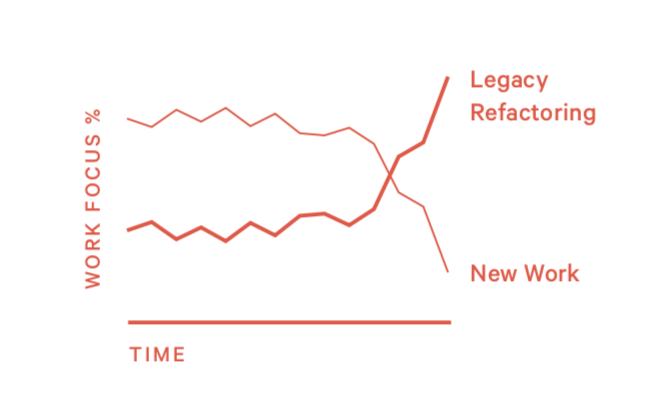
2)如何处理这种情况?
- 给出在当前阶段,什么样的实现是合适的,不需要再优化了。
模式14:临上线前提交PR (Just One More Thing)

如果只有少部分人在迭代结束的时候才提交代码,那么这是一个需要改正的习惯。如果所有人都这样,说明流程或团队文化有问题。
1)如何发现这个问题?
- 在核心PR merge之后又提交了大量新代码
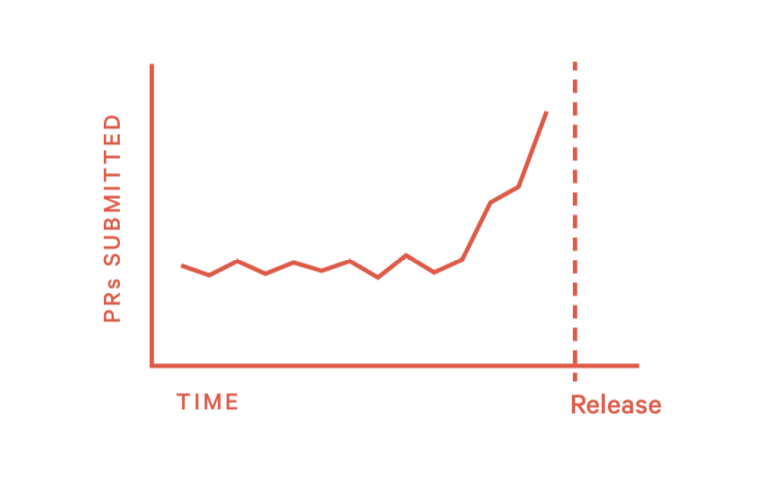
2)如何处理这种情况?
- 开发前预估工时,确定提交PR的日期(人力资源、工作量和上线时间三者是联动的)
- 跟做的不好的同学聊天,解释PR提的晚会造成的影响,站在他们的角度换位思考
模式15:不经思考的merge PR (Rubber Stamping)

一般有几种情况:
- 资深工程师提交一个PR,reviewer默认是没问题的
- 工程师不认可code review的价值
- 没有时间充分review
Code review会带来很多好处:
- 提升代码质量
- 知识共享
- 找到问题的更优解
- 促进团队合作和获取指导资源的一种渠道
1)如何发现这个问题?
- PR产生后很快被merge
- 很少会在PR中对实现方式进行讨论
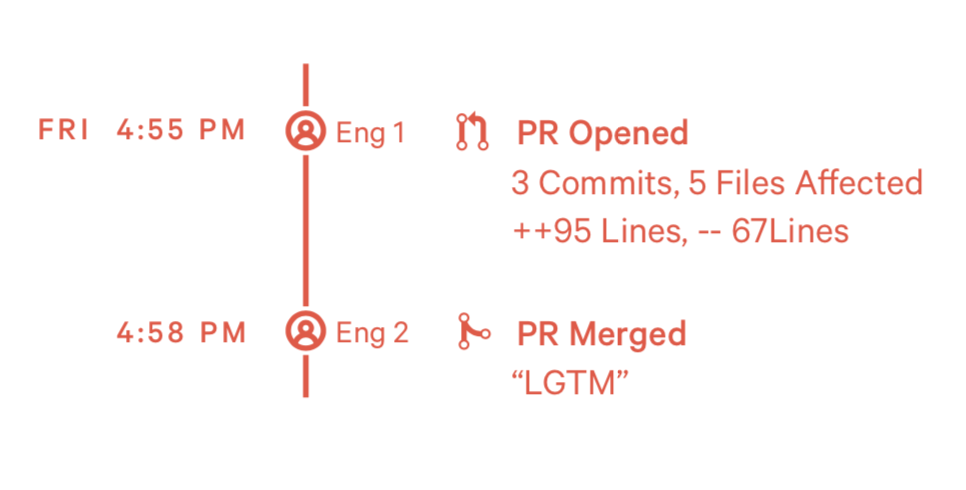
2)如何处理这种情况?
- 具体举例说明什么样的review是好的review
- 看是不是因为需要review的代码太多、提交太晚导致的
模式16:知识谷仓 (Knowledge Silos)

谷仓效应指企业内部因缺少沟通,部门间各自为政,只有垂直的指挥系统,没有水平的协同机制,就象一个个的谷仓,各自拥有独立的进出系统,但缺少了谷仓与谷仓之间的沟通和互动。
在软件开发中,当知识没有充分共享时,会产生知识谷仓。比如三个人总是互相review代码,没有其他工程师能够参与进来。时间长了也会导致习惯性信任对方的代码没有问题,会导致很多PR没有经过详细的review就被merge。
1)如何发现这个问题? 2~3人总是互相review代码
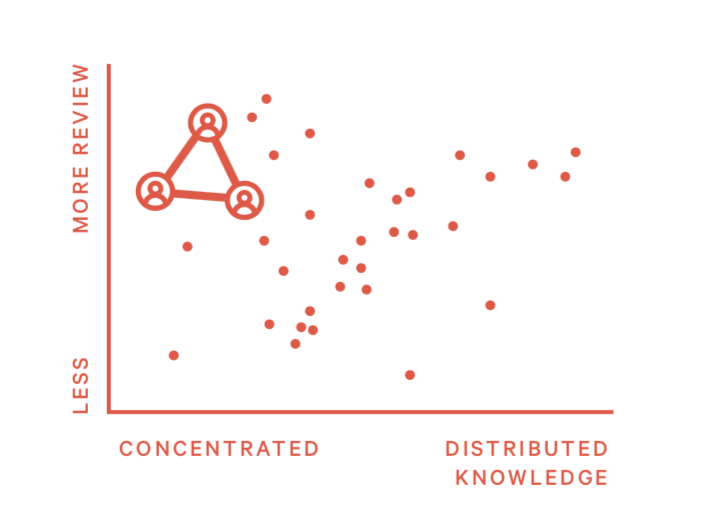
2)如何处理这种情况?
- 找其他人review他们的代码,通过这种方式也可以测试是否有工程师快速上手产生知识谷仓的代码
- 让他们review其他人代码
模式17:合并自己的PR (Self Merging PRs)

合并自己的代码很容易引入bug,很多公司都不允许做这种操作。
1)如何发现这个问题?
- 合并自己的PR
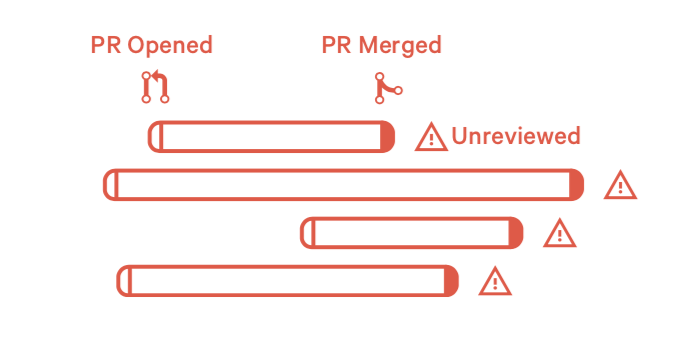
2)如何处理这种情况?
- 把系统设置为不允许merge自己的代码;如果不强制,也要保证merge之后会有人再review
- 如果需要紧急上线,通知测试同学参与进来
- 找这些同学聊天,搞清楚原因,明确预期。如果是资深工程师这样做,鼓励他们充分参与code review流程,因为其他工程师会效仿他的行为
模式18:长时间无法merge的PR (Long Running PRs)

这里指的是超过一周还没有merge的PR。放置时间太长会与最新的代码产生冲突,也会影响迭代进度。
1)如何发现这个问题?
- 按照提交时间对PR倒排

2)如何处理这种情况?
- PR的提交者应该肩负起这个责任,提醒其他同学review,如果出现意见不一致,想办法解决它。
模式19:高巴士因子 (High Bus Factor)

巴士因子是指几个核心员工收到不可抗力影响无法工作时,项目会瘫痪。员工的数量即为巴士因子。高巴士因子代表知识共享的程度更高。否则代表有筒仓效应。
1)如何发现这个问题?
- 观察工程师是否只固定review小范围的代码
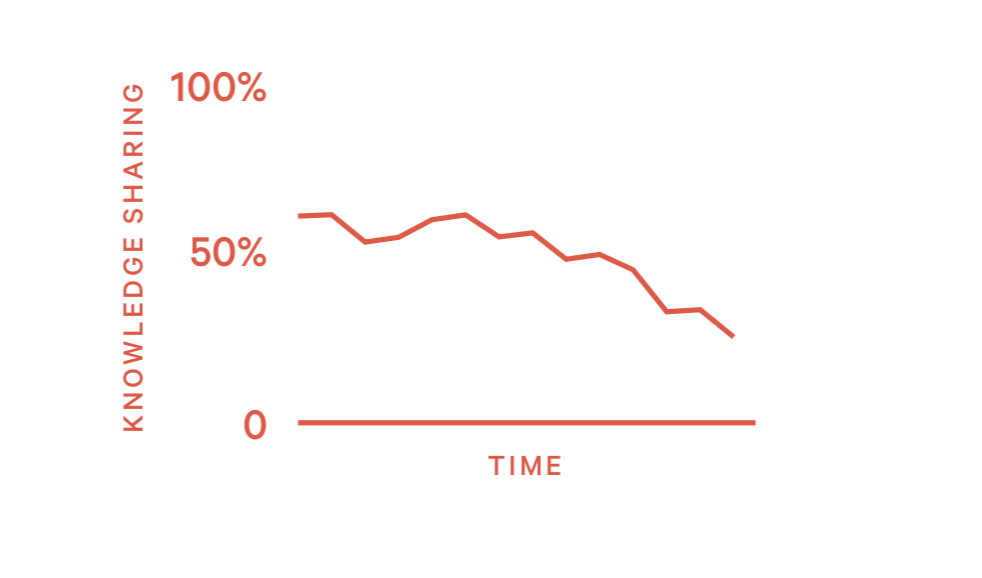
2)如何处理这种情况?
- 当PR比较小、比较频繁,每个人都能参与到review的讨论中时,更容易达到知识共享的目标。
模式20:迭代复盘 (Sprint Retrospectives)

在迭代复盘会上回顾迭代的目标、发生了什么、为什么发生、计划下一步做什么。
1)如何发现这个问题?
- 利用统计数据说明在这个迭代发生了什么
2)如何处理这种情况?
- 教会每位同学如何利用数据分析工作情况,告诉他们哪些是值得鼓励的那些要尽可能避免。