Supernan1994's Personal Blog
[Paper Reading][OSDI’10] Finding a needle in Haystack: Facebook’s photo storage
这篇论文2010年发表在OSDI上,当时Facebook着面临一个没有人解决过的问题:由于社交网络的业务特点,用户会上传大量小图片,如何以最低成本提供最高效稳定的小文件读写服务是这篇论文探讨的核心问题。
文中所提出的思想非常简洁,概括来说,作者认为linux的文件系统在读文件时需要做多次的磁盘操作,其中对文件元信息inode的读取操作是限制小文件服务读呑吐量的主要原因。因此作者抛弃了linux文件组织形式,在内存中构建最适合业务特点的自建索引加速查询效率。
尽管想法朴素,但Haystack具有很高的商业价值,成为此后海量小文件存储的事实标准。
1. 业务特点
1.1 数据量
当时facebook存储了2600亿图片数据,总数据量20P(平均一张图片86k)。每天有1亿张图片的数据量增长。
1.2 并发量
请求有增删改查四种类型,数据访问的频率是:一次创建,经常读取,从不修改,很少删除。对于需要重点关注的查看和上传请求来说,根据统计结果:
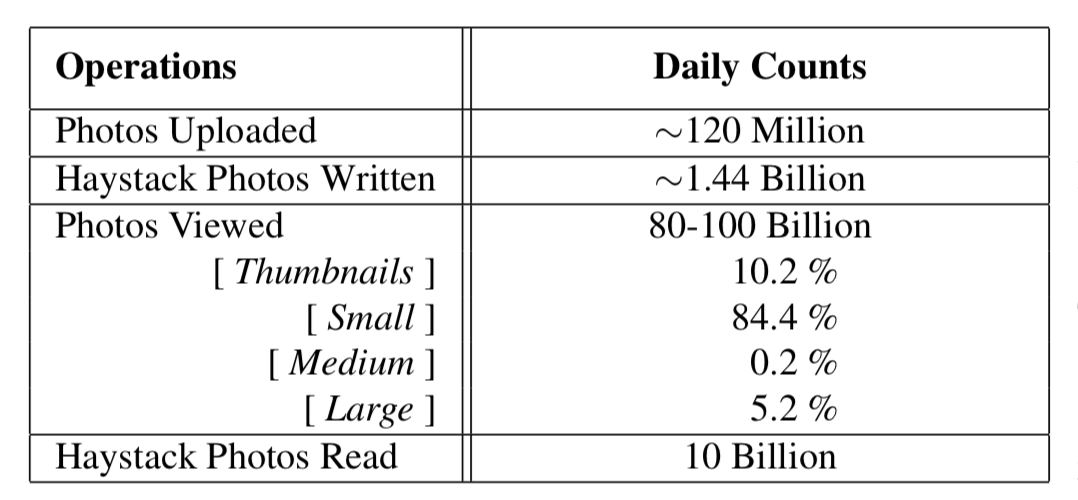
- 查看
- 流量峰值时每秒处理100w请求
- 84.4%是小文件
- CDN可以拦截掉90%的查看请求,只有10%需要文件系统处理。
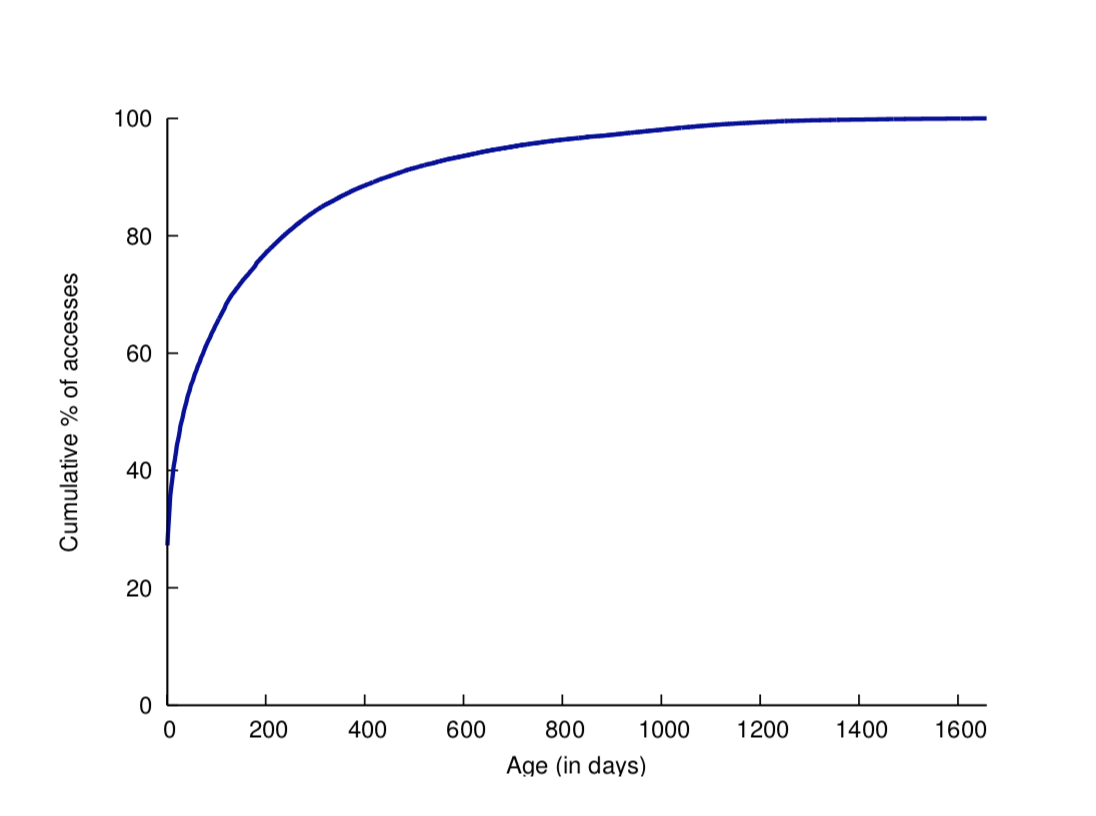
- 图片刚上传的前几天访问最频繁,随时间推移访问量越来越少,呈长尾分布。
- 上传
- 在Haystack实现中会对数据做3份冗余存储,同时由于业务需要保存4份不同尺寸的图片,因此一次上传会产生12次创建图片的请求。
2. 优化目标
- 高吞吐低延迟
- 容错性
- 高性价比
- 简单易维护
3. 背景知识
对于海量小文件服务,考虑性价比和持久化的因素,一般使用磁盘对数据进行保存。这一小节会简单介绍磁盘读写和linux文件系统的工作原理,这可以让我们更好的了解Haystack的优化动机。
3.1 磁盘1
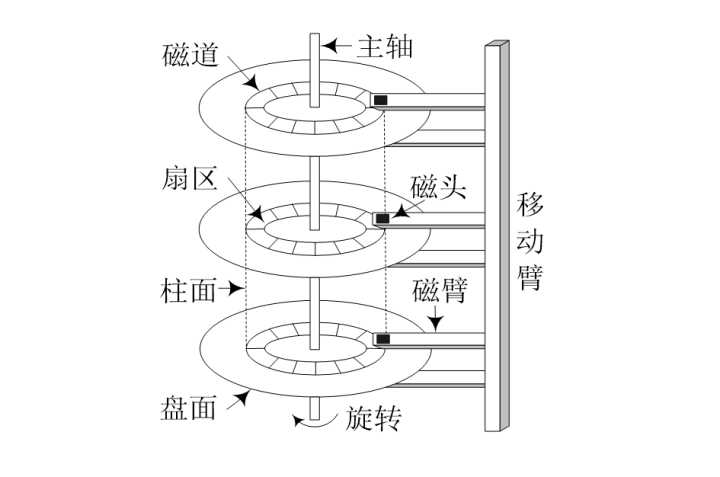
3.1.1 基本概念
- 主轴:以恒定速度旋转(90~250转/s)
- 盘片:每条磁盘有1~5个盘片
- 磁道:每个盘片有5w~10w磁道
- 柱面:每个磁道相同半径的磁道组成一个柱面
- 扇区:一般512B,每个磁道有500~2000扇区,外侧磁道比内侧磁道扇区更多
- 磁头:每个盘片正反两面各有一个磁头,磁头可以通过磁臂内外移动定位到特定磁道(寻道操作)上
- 块(页):逻辑单元,一般4KB,包含固定数目的连续扇区,是磁盘和内存进行数据传输的基本单位
3.1.2 性能度量
访问某个扇区的数据的步骤如下:
- 通过磁臂移动定位到特定磁道
- 通过磁盘旋转定位到特定扇区
- 从扇区里读取数据
这3个步骤分别对应衡量磁盘性能的3个维度:
- 平均寻道时间:一般2~30ms
- 旋转等待时间:60~250转/s = 4~11ms/转;平均旋转等待时间:2~5.5ms/转
- 数据传输率:25~100MB/s,外侧磁道比内侧磁道更快
假设现在有一块磁盘,平均寻道时间=15ms,平均旋转等待时间=3ms,数据传输率=50MB/s。做一次扇区定位所花费的时间约等于顺序读取 (15ms+3ms)*(50MB/s/1000) = 900KB 数据的时间。由于两种操作效率上存在差异,对于磁盘这种存储介质,应该尽量减少扇区定位操作,做更多的顺序读写。
3.2 linux文件系统23
下图展示了linux文件系统从文件读写接口到物理硬件的完整技术栈。本小节主要关注VFS层,当我们发起open,read文件命令时,操作系统是如何通过文件名读取到文件内容。
VFS(Virtual File System)是linux提供的虚拟文件系统,它向下游应用方屏蔽文件系统(如EXT2, FAT, NFS etc.)的实现细节,暴露统一的接口(如open, read, write etc.);同时支持在一个VFS上挂载多种实现的文件系统。

3.2.1 基本概念
首先,我们先了解一下VFS实现中一些关键的数据结构的用途和组织形式。EXT2是linux最经典的文件系统,涉及到的地方会具体展开描述。
1)superblock
每一个挂载的文件系统对应一个superblock。superblock中包括文件系统的基础信息,比如:设备信息、块大小、根目录索引(s_root)等。
/include/linux/fs.h
struct super_block {
dev_t s_dev;
unsigned long s_blocksize;
struct file_system_type *s_type;
struct super_operations *s_op;
struct dentry *s_root;
...
}
在EXT2中也有superblock的概念,在格式化后,superblock会被分为以下几个区域:
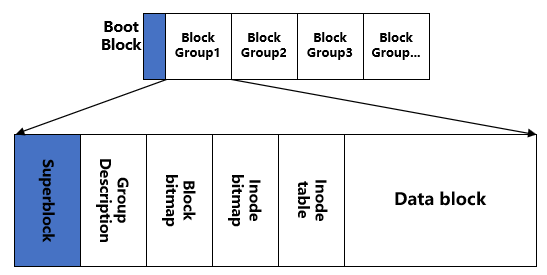
2)inode(index node)
每个文件和文件目录(是一个特殊文件)都会对应一个inode。inode中包括文件的一些基础信息,比如:权限、大小、更新时间;也包含文件所在磁盘的元信息(super_block)、文件目录(i_dentry)、文件块和磁盘块的地址映射关系(address_space)。
/include/linux/fs.h
struct inode {
unsigned long i_ino;
umode_t i_mode;
uid_t i_uid;
gid_t i_gid;
kdev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
struct timespec i_ctime;
struct timespec i_mtime;
struct super_block *i_sb;
struct inode_operations *i_op;
struct address_space *i_mapping;
struct list_head i_dentry;
struct hlist_node i_hash;
...
}
VFS会在内存中用哈希表缓存inode,如果使用时没有在缓存中查到,会从文件系统中查询。
在EXT2的实现中,有特定的一块独立于存储数据的区域来专门存储inode(即superblock中的inode table),每个inode大小为128B/256B。而一个block id会占用4B,显然inode的空间只能记录很少的block id。EXT2为解决这个问题,利用间接指向将block id记录下来。

假设格式化磁盘时,我们设置1个block大小是1KB:
- 第一级直接指向可以记录12*1KB=12KB的数据信息。
- 第一级间接指向可以记录256*1KB=256KB的数据信息。
- 第二级间接指向可以记录256*256*1KB=65MB的数据信息。
- 第三级间接指向可以记录256*256*256*1KB=16GB的数据信息。
通过计算可以了解到:
- 间接指向可以扩大inode存储的文件大小
- 随着block容量的扩大,文件的max size成指数型增长
- 文件越大,打开文件需要加载的间接指向越多,耗时越长
3)dentry
VFS会将文件系统的所有目录构建成一棵树,dentry表示树的节点。dentry中包括目录指向的文件inode(d_inode)、父目录的dentry节点(d_parent)、子目录节点(d_subdirs)、路径名(d_name)、路径缓存(d_hash)等信息。
/include/linux/dcache.h
struct dentry {
struct inode *d_inode;
struct hlist_bl_node d_hash;
struct dentry *d_parent;
struct qstr d_name;
struct super_block *d_sb;
struct dentry_operations *d_op;
struct list_head d_subdirs;
...
}
struct qstr {
const unsigned char *name;
unsigned int len;
unsigned int hash;
};
路径缓存(d_hash)起到加快查询路径的速度的作用,在内存中用哈希表缓存了一部分路径(小于15个字符的短路径)的dentry信息。这一模块利用了LRU算法做缓存淘汰。 当没有命中缓存时,会从目录文件中读取目录信息。
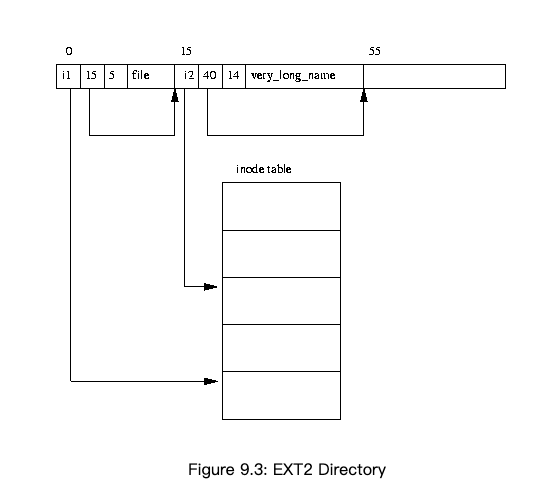
4)file
file结构体代表打开的文件,当一个文件被打开多次时,会产生多个file实例,每个都关联同一个inode,有独立的读写偏移量。
/include/linux/fs.h
struct file {
struct dentry *f_dentry;
struct vfsmount *f_vfsmnt;
struct file_operations *f_op;
mode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
unsigned int f_uid, f_gid;
unsigned long f_version;
...
}
3.2.2 读文件流程
当应用层代码执行os.Open操作时,会发起open的系统调用。VFS会使用文件目录依次匹配dentry树形结构,查询到文件系统对应的inode节点。在构造dentry过程中,如果路径没有被系统缓存,需要从目录文件中查询子路径(第一次磁盘操作)。查询到inode节点后,可以根据地址映射关系找到文件的块地址,如果inode信息没有被系统缓存,需要从inode table中读取信息(第二次磁盘操作)。会构造file结构体关联inode,挂载在进程的结构体中,返回给应用程序。
当应用层代码执行os.Read操作时,系统会根据inode中块地址定位到磁盘扇区获取文件内容(第三次磁盘操作)。
在linux实现中,读一个文件需要进行3次磁盘操作。结合3.1节我们知道每次寻道的时间代价很大,facebook认为读取小文件元数据所占用磁盘IO(前两次磁盘操作)是影响读吞吐量的根本原因。
4. 常见做法
通常小文件存储服务会将数据存储在磁盘上,前边放一个CDN拦截热数据的请求。没有被缓存的文件直接从磁盘中读文件返回。
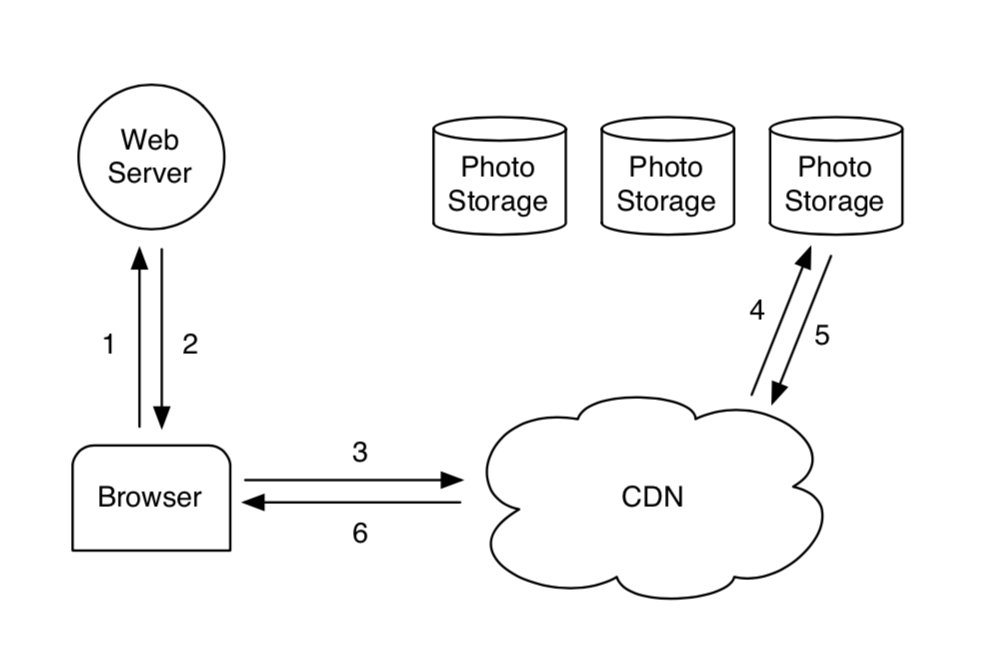
在最初的实现里,facebook使用NFS4提供服务,用户通过外网访问文件时,文件系统前也使用CDN做了缓存,大部分请求可以被CDN处理,但会有10%落到NFS上,NFS会根据路由信息将请求转发到下游的NAS上。
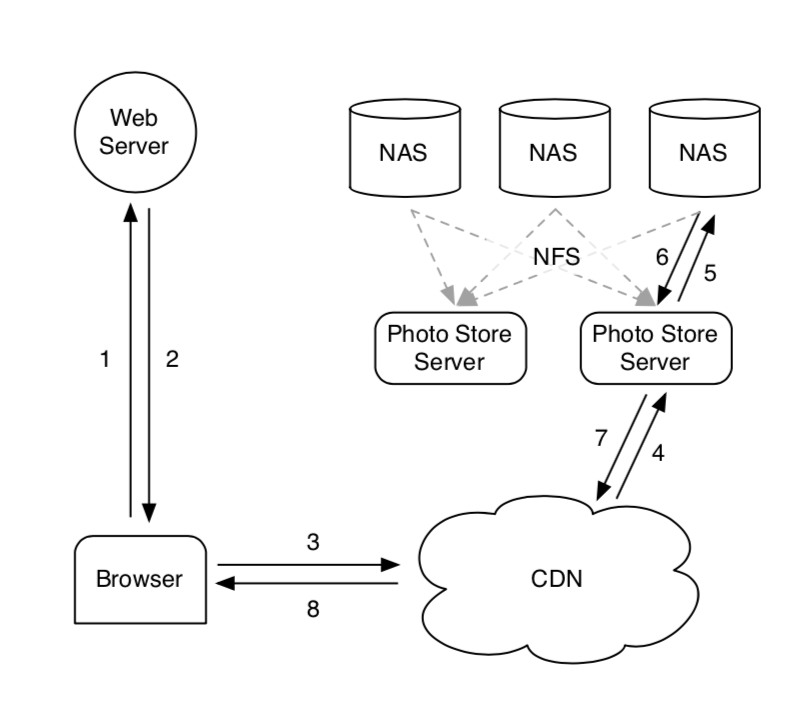
小文件场景中经常会在目录里放上千个文件,导致目录元信息文件特别大很难被NAS有效的缓存,后来他们将每个目录下的文件控制在1000个以内。即使这样也会有3次磁盘操作,所以他们又改了内核源码,加了一个open_by_filehandle的系统调用,通过这个方法打开文件,可以利用缓存的文件句柄。
尽管做了很多优化,仍有一些请求会绕过缓存做多次磁盘IO。缓存使用的越多,越多请求可以被及时响应,但成本也会随之增高,到达一定程度后增加缓存不再具有性价比。当优化目标是TP90+的时候,应该去优化磁盘IO。所以作者设计了Haystack以达到更好的price/performance的平衡。
5. Haystack设计与实现
由于时间主要消耗在查询dentry和inode上。Haystack的主要设计理念是:
- 把vfs中一些无关的数据(如权限等)去掉,把文件元信息缩到很小,全部放到内存里。
- 把小文件打包存储在大文件里,每次请求直接通过内存定位到小文件的位置,磁盘操作只做目标文件内容读取。
- 由于业务一次写入、从不修改、很少删除的特点,可以通过顺序写最大化写操作的效率,基本不会产生磁盘碎片。
5.1 基础组件
Haystack系统主要分3个部分:
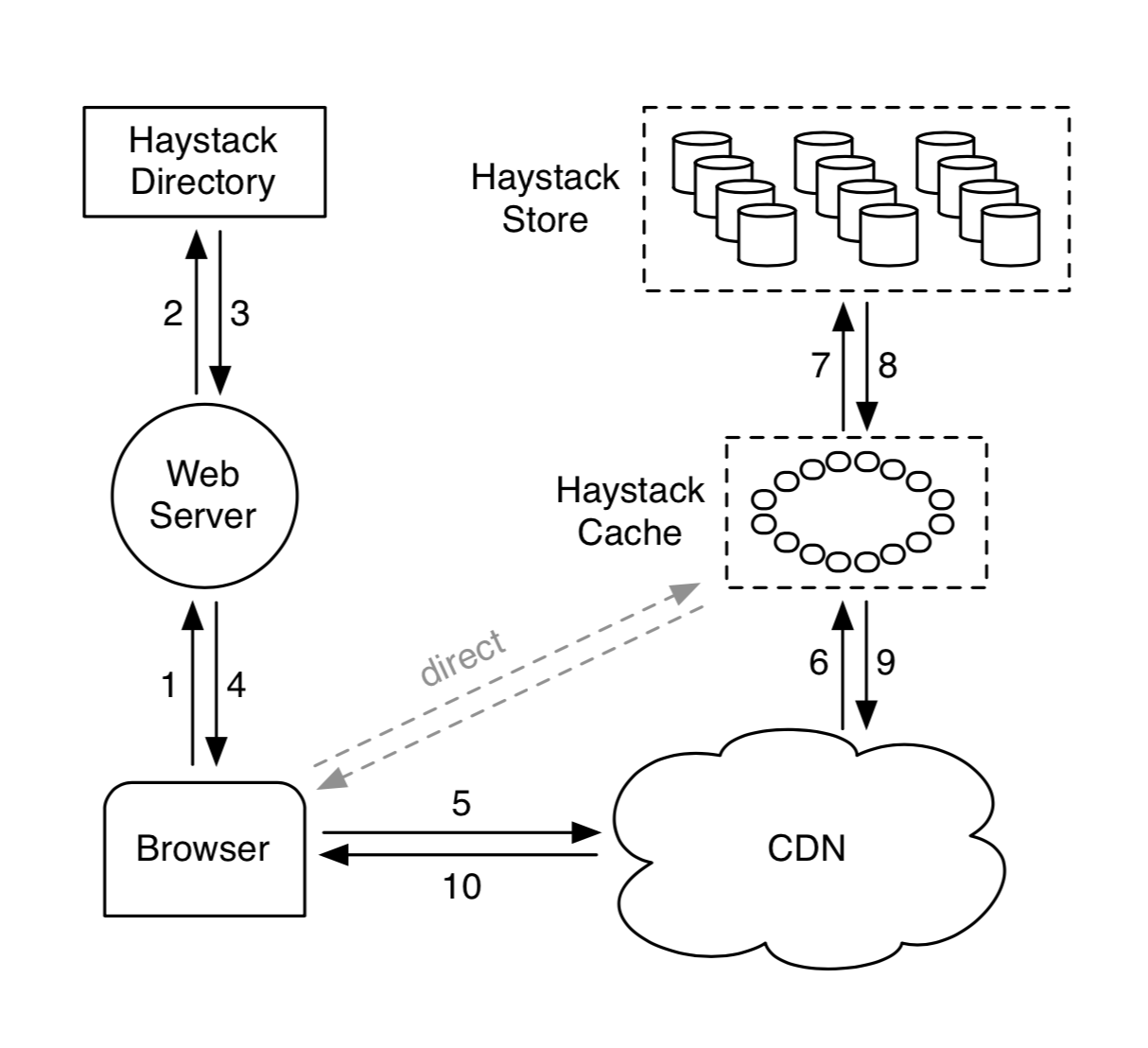
- Store:存储源文件,将小文件打包到大文件(100GB)里。每个大文件叫做一个physical volume,一台机器可以有多个volume,不同机器上的physical volume的副本可以组成一组logical volume。
- Directory:存储logical volume和physical volume的映射关系。
- Cache:在CDN后再缓存一层,防止CDN故障。
5.1.1 Directory
Directory主要有4个作用:
- 存储logical volume和physical volume的映射关系
- 负载均衡对physical volume的请求
- volume满时设置为只读
- 决定请求是由CDN还是Cache处理(用来调整CDN)
Directory的数据存储在分布式的memcache里。
5.1.2 Cache
Cache的数据存放在分布式的hash table里,用photo id作为key。只有两种情况图片会被缓存:
- 请求是从用户侧来的,不是从CDN来的:因为无法命中CDN的请求通常也无法命中Cache。
- 请求发往可写的Store节点:可写的Store节点一般存储的是最新上传的数据,访问量较大;通常磁盘在只读和只写情况下性能较好,读写交错的情况性能不会很好(这个原因没有细说,我理解是只读/只写时做磁盘顺序扫描较多,读写交错需要频繁做随机读写)。
5.1.3 Store
一台Store机器上可以有多个physical volume,每个100GB,名字叫做/hay/haystack/_<logical volume id>,每个volume的文件描述符会被缓存在内存里。Store使用XFS5文件系统。小文件按照下图的形式顺序排列在磁盘上:
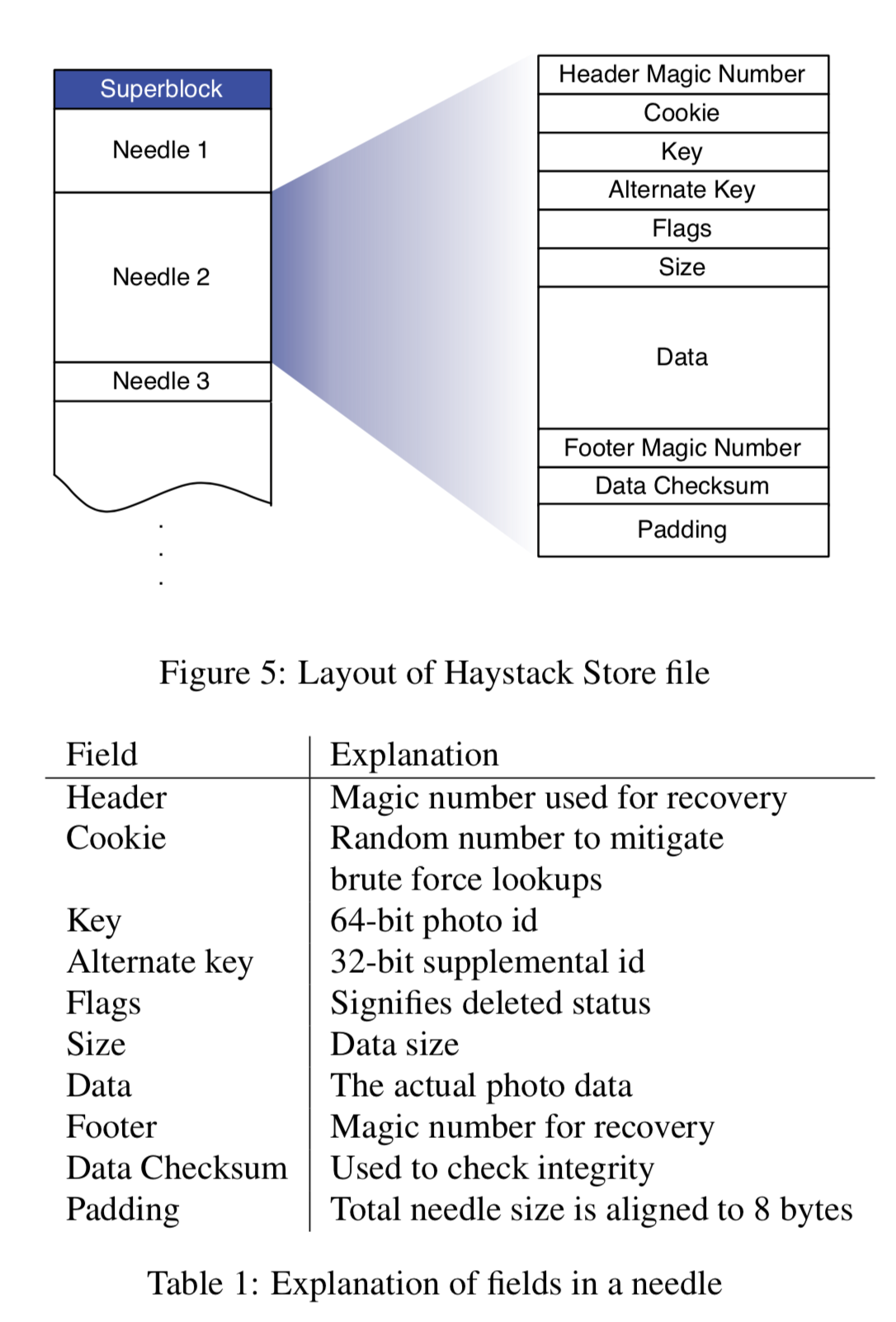
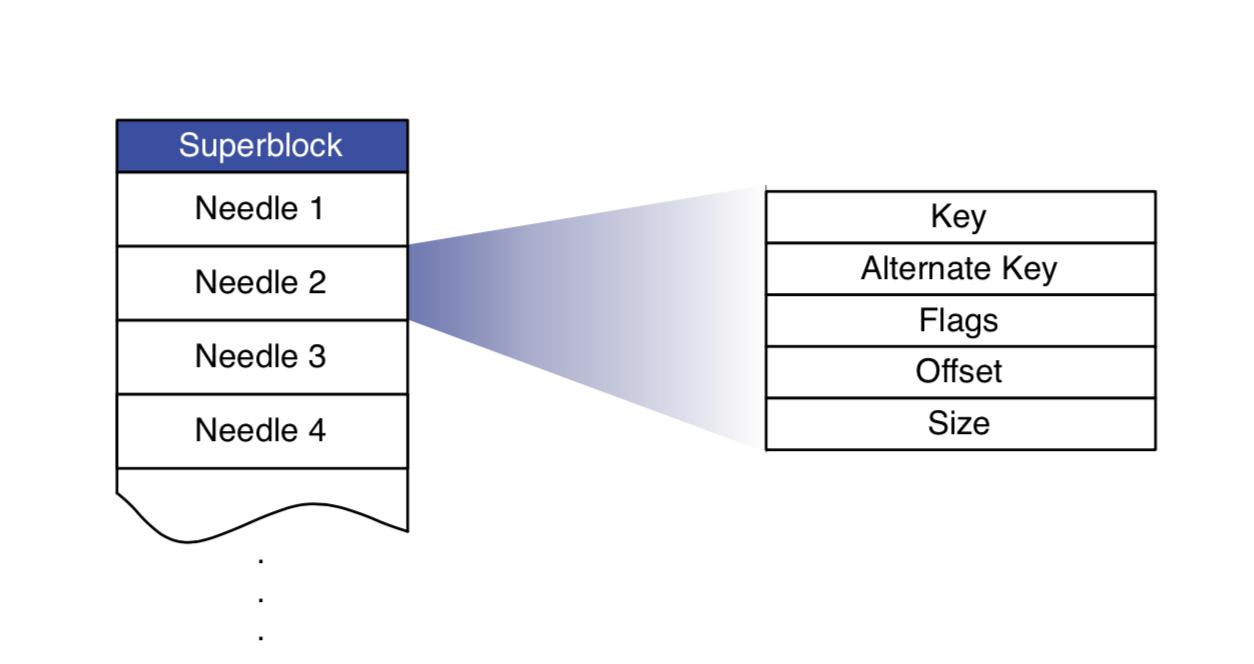
为了加快查询效率,每个volume会有一个内存索引,记录<key, alterate key>(这里alterate key是facebook的一个业务参数,无需关心)和文件<size, offset>(offset=0时代表文件已删除)的对应关系。每张图片大概占用10B内存,由于每张图片会保存4个尺寸的备份:
64bit[key] + 4photos * (32bit[alterate key] + 16bit[size] + 2B[hash table overhead]) = 40B(这里没说offset,不知道是什么原因)。
文件元信息的内存消耗大概是EXT2的1/10,XFS的1/50。
内存索引会异步的持久化到磁盘上,一旦宕机,重启时会重新加载内存索引。使用这个索引文件进行故障回复比读全量volume要快得多。
5.2 读写流程
5.2.1 读请求
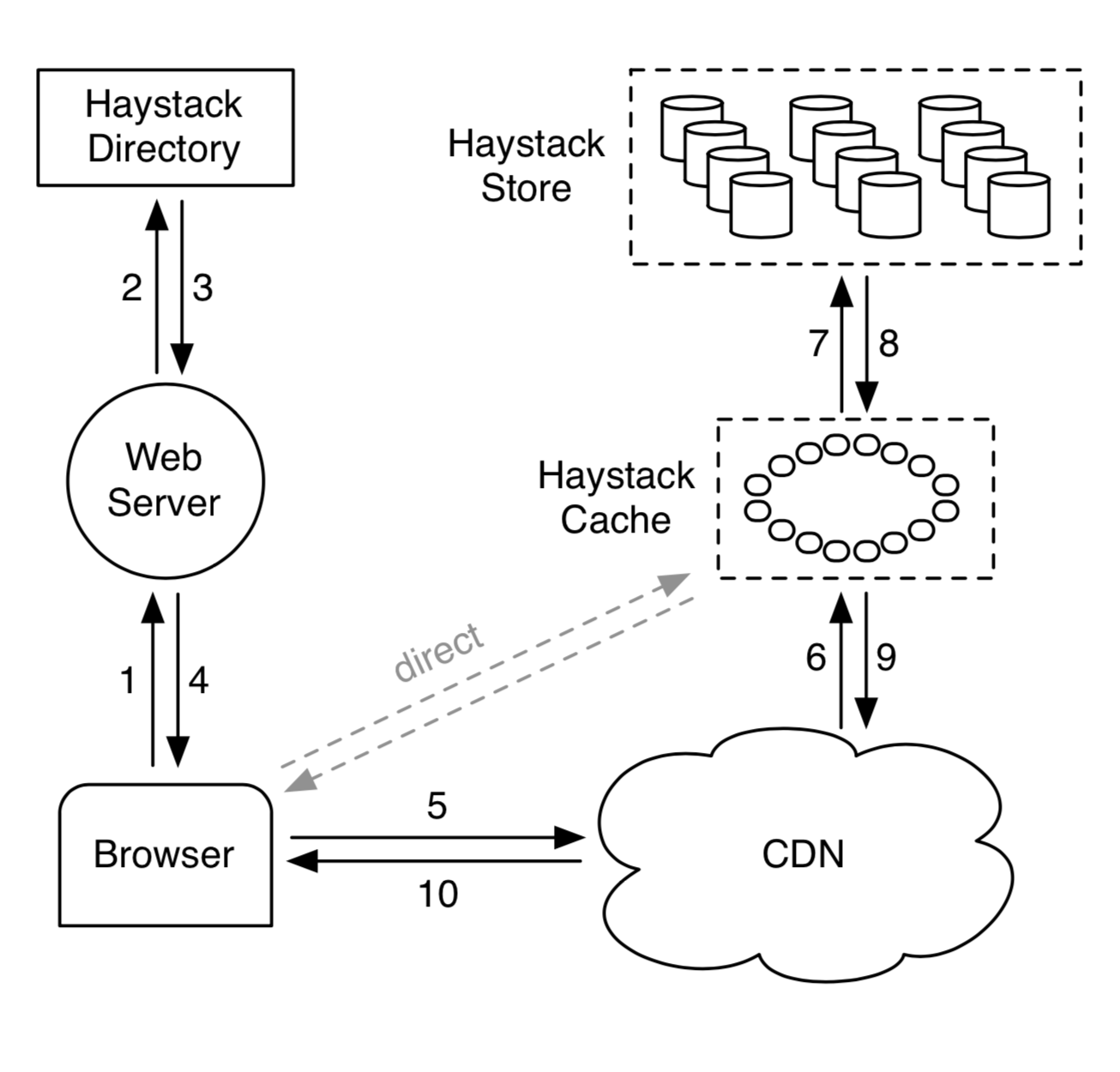
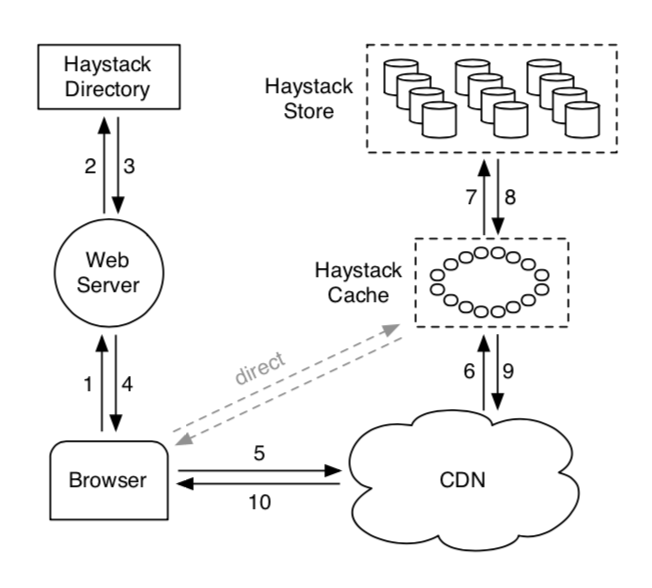
- 2+3:业务后端调用Directory构造图片URL,格式如下:
http://⟨CDN⟩/⟨Cache⟩/⟨Machine id⟩/⟨Logical volume, Photo⟩
photo包括:key, alterate key, cookie。
Directory会决定本次请求是否走CDN,进行负载均衡,确定发往哪台机器。 - 6:CDN根据
⟨Logical volume, Photo⟩查找缓存,如果没有查到,就把URL里CDN一段替换掉,将请求透传到Cache。 - 7:Cache根据
⟨Logical volume, Photo⟩查找缓存,如果没有查到,就把URL里Cache一段替换掉,将请求透传到Store。 - 8:Store根据
⟨Logical volume, Photo⟩查找<size, offset>,如果图片已经被删除(offset=0),直接报错。否则去查Store文件。 - 8:校验cookie是否合法,如果合法返回图片内容。校验cookie这一步是为了保证发往Store的请求是经过业务后端和Directory认证过的,不允许通过暴力碰撞访问Store的其他图片。
5.2.2 写请求
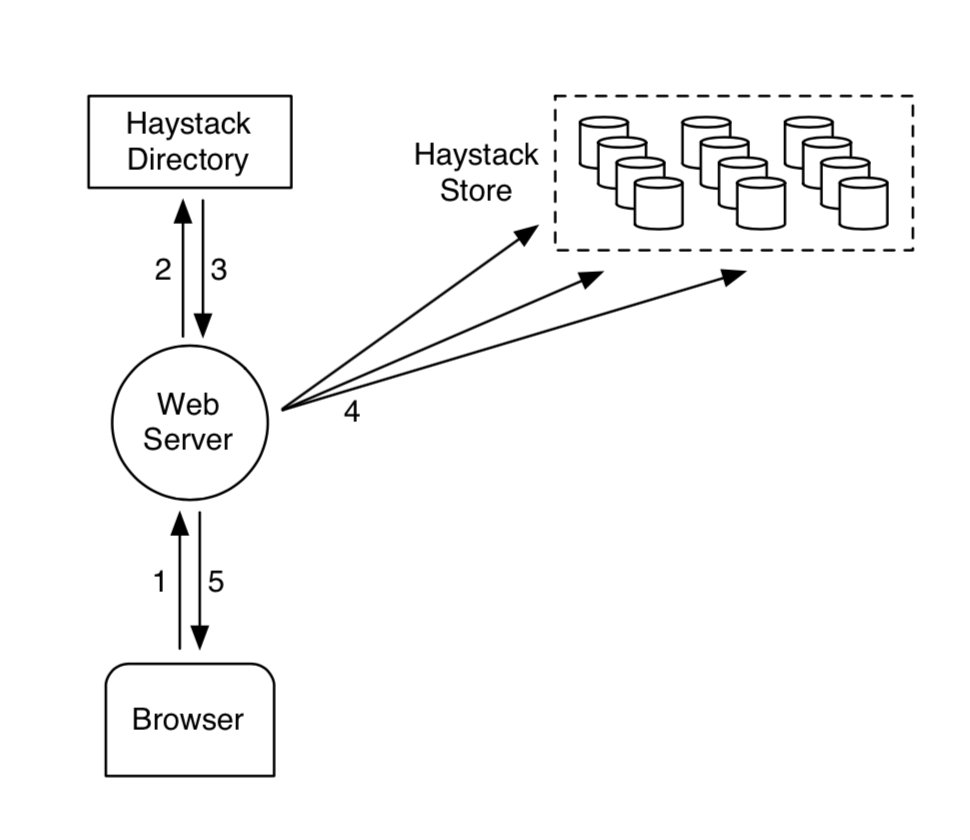
- 2:业务后端调用Directory获取可写的Store和cookie。
- 4:业务后端向多个Store发起写请求(写多次用来备份)。
- 4:Store接收到请求后先写内存索引,再同步追加写Store文件,最后异步追加索引文件。
5.3 冗余存储
主要有两种情况会造成数据的冗余存储:
- 删除文件:只会修改标志位,不会删除原文件
- 重复上传的文件:修改索引文件的偏移量,旧文件的位置不会再被访问
facebook会定时对Store文件做整理,删除这些不再使用的数据。
6. 参考文献
-
The Linux kernel: https://www.win.tue.nl/~aeb/linux/lk/lk-8.html ↩
-
The Linux Documentation Project: http://www.tldp.org/LDP/tlk/tlk.html ↩
-
The Sun Network Filesystem: Design, Implementation and Experience: http://www.cs.ucf.edu/~eurip/papers/sandbergnfs.pdf ↩
-
XFS Filesystem Structure: http://www.dubeiko.com/development/FileSystems/XFS/xfs_filesystem_structure.pdf ↩